Optima Consulting & ManagementDEEP LEARNING FOR FRESHERS
¿Qué es el Deep Learning?
El Deep Learning o Aprendizaje Profundo, es un subconjunto del Machine Learning o Aprendizaje Automático que se basa completamente en redes neuronales artificiales. Debido a que las redes neuronales están diseñadas para imitar el cerebro humano, el aprendizaje profundo también es una imitación del cerebro humano. No tenemos que programar explícitamente todo en el aprendizaje profundo. Entrenamos un modelo con un conjunto de datos de entrenamiento y lo mejoramos hasta que el modelo prediga casi correctamente en el conjunto de datos de prueba y validación también. Los modelos de aprendizaje profundo son capaces de enfocarse en características precisas por sí mismos, con solo un pequeño aporte del programador, y son muy útiles para resolver el problema de la dimensionalidad. El aprendizaje profundo no es un concepto nuevo. Ha existido durante bastante tiempo. Está de moda en estos días ya que no tenemos casi tanta potencia de procesamiento o tantos datos como tenemos ahora. A medida que la potencia de procesamiento ha aumentado tremendamente en los últimos 20 años, el aprendizaje profundo y el aprendizaje automático han entrado en escena. Mientras trabajaba en una red de aprendizaje profundo a mediados de la década de 1960, Alexey Grigorevich Ivakhnenko publicó el primer general. Esencialmente, es un subconjunto de aprendizaje automático que realiza extracción y transformación de características utilizando un gran número de unidades de procesamiento no lineales. Cada una de las capas subsecuentes utiliza la salida de la capa anterior como entrada. El aprendizaje profundo es apropiado para una variedad de aplicaciones, incluyendo visión por computadora, reconocimiento de voz, procesamiento de lenguaje natural, y así sucesivamente.
Entonces, ¿Qué se entiende por Redes Neuronales en el contexto del Deep Learning?
Las Redes Neuronales son sistemas artificiales que se asemejan mucho a las redes neuronales biológicas en el cuerpo humano. Una red neuronal es un conjunto de algoritmos que intenta reconocer relaciones subyacentes en un conjunto de datos utilizando un método que imita cómo funciona el cerebro humano. Sin reglas específicas para una tarea, estos sistemas aprenden a realizar tareas al ser expuestos a una variedad de conjuntos de datos y ejemplos. La idea es que en lugar de ser programados con una comprensión predefinida de estos conjuntos de datos, el sistema derive rasgos identificativos a partir de los datos que se le proporcionan. Las redes neuronales se basan en modelos computacionales de lógica de umbral. Debido a que las redes neuronales pueden adaptarse a cambios en la entrada, pueden producir el mejor resultado posible sin necesidad de rediseñar los criterios de salida.
¿Qué aplicaciones tiene el Deep Learning?
- Reconocimiento de patrones y procesamiento del lenguaje natural.
- Reconocimiento y procesamiento de imágenes.
- Traducción automatizada.
- Análisis de sentimientos.
- Sistemas para responder preguntas.
- Clasificación y detección de objetos.
- Generación de escritura a mano por máquina.
- Generación automática de texto.
- Colorización de imágenes en blanco y negro.
¿Qué es la tasa de aprendizaje o el Learning Rate de estos algoritmos?
La tasa de aprendizaje es un número que varía de 0 a 1. Es uno de los hiperparámetros ajustables más importantes en los modelos de entrenamiento de redes neuronales. La tasa de aprendizaje determina qué tan rápido o lentamente un modelo de red neuronal se adapta a una situación dada y aprende. Un valor de tasa de aprendizaje más alto indica que el modelo solo necesita unos pocos epochs de entrenamiento y produce cambios rápidos, mientras que una tasa de aprendizaje más baja indica que el modelo puede tardar mucho tiempo en converger o puede que nunca converja y se quede atascado en una solución pobre. Como resultado, se recomienda establecer un buen valor de tasa de aprendizaje mediante ensayo y error en lugar de usar una tasa de aprendizaje que sea demasiado baja o demasiado alta.
¿Qué ventajas y desventajas tienen las Redes Neuronales?
Entre las ventajas más importantes encontramos:
Las redes neuronales son extremadamente adaptables y pueden ser utilizadas tanto para problemas de clasificación como de regresión, así como para problemas mucho más complejos. Las redes neuronales también son bastante escalables. Podemos crear tantas capas como deseemos, cada una con su propio conjunto de neuronas. Cuando hay muchos puntos de datos, se ha demostrado que las redes neuronales generan los mejores resultados. Son mejores utilizadas con datos no lineales como imágenes, texto, etc. Se pueden aplicar a cualquier dato que se pueda transformar en un valor numérico.
Una vez que el modelo de red neuronal ha sido entrenado, entregan resultados muy rápido. Por lo tanto, son efectivas en términos de tiempo.
Por otro lado, entre sus desventajas encontramos:
El aspecto de "caja negra" de las redes neuronales es una desventaja bien conocida. Es decir, no tenemos idea de cómo o por qué nuestra red neuronal produjo un cierto resultado. Cuando introducimos una imagen de un perro en una red neuronal y predice que es un pato, podemos encontrar difícil entender qué la llevó a hacer esta predicción. Se tarda mucho tiempo en crear un modelo de red neuronal. Los modelos de redes neuronales son computacionalmente costosos de construir porque se necesitan realizar muchas computaciones en cada capa. Un modelo de red neuronal requiere significativamente más datos que un modelo de aprendizaje automático tradicional para entrenar.
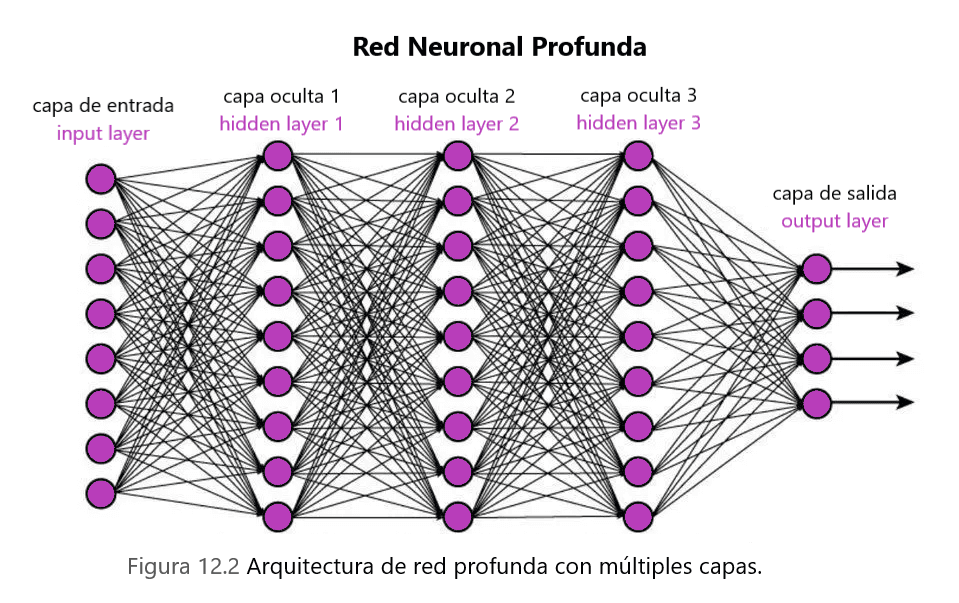
Entonces, ¿cómo podemos explicar que es una Deep Neural Network?
Un tipo de red neuronal artificial (ANN) que tiene numerosas capas entre las capas de entrada y salida se conoce como una red neuronal profunda (DNN). Las redes neuronales profundas son redes neuronales que utilizan arquitecturas profundas. El término "profundo" se refiere a funciones que tienen un mayor número de capas y unidades en una sola capa. Es posible crear modelos más precisos agregando más capas y de mayor tamaño para capturar niveles más altos de patrones.
Entre los distintos tipos de Deep Neural Networks existen:
- Red Neuronal FeedForward: Este es el tipo más básico de red neuronal, en el cual el control del flujo comienza en la capa de entrada y se mueve hacia la capa de salida. Estas redes solo tienen una capa o una capa oculta única. No hay un mecanismo de retropropagación en esta red porque los datos solo fluyen en una dirección. La capa de entrada de esta red recibe la suma de los pesos presentes en la entrada. Estas redes se utilizan en el método de reconocimiento facial basado en visión por computadora.
-Red Neuronal de Función de Base Radial: Este tipo de red neuronal generalmente tiene más de una capa, preferiblemente dos. En este tipo de red se determina la distancia relativa desde cualquier ubicación hasta el centro y se pasa a la siguiente capa. Para evitar apagones, las redes de base radial se utilizan comúnmente en sistemas de restauración de energía para restablecer la energía en el período más corto posible.
-Perceptrón Multicapa (MLP): Un perceptrón multicapa (MLP) es un tipo de red neuronal artificial (ANN) de alimentación directa. Los MLP son las redes neuronales profundas más simples, que consisten en una sucesión de capas completamente conectadas. Cada capa sucesiva está compuesta por una colección de funciones no lineales que son la suma ponderada de todas las salidas de la capa anterior (completamente conectadas). El reconocimiento de voz y otros sistemas de aprendizaje automático dependen en gran medida de estas redes.
-Red Neuronal Convolucional (CNN): Las Redes Neuronales Convolucionales se utilizan principalmente en visión por computadora. A diferencia de las capas completamente conectadas en los MLP, una o más capas de convolución extraen características simples de la entrada realizando operaciones de convolución en los modelos de CNN. Cada capa está compuesta por funciones no lineales de sumas ponderadas en diversas coordenadas de subconjuntos espacialmente cercanos de las salidas de la capa anterior, lo que permite reutilizar los pesos.
El sistema de inteligencia artificial aprende a extraer automáticamente las propiedades de estas entradas para cumplir una tarea específica, como la clasificación de imágenes, la identificación facial y la segmentación semántica de imágenes, dadas una secuencia de imágenes o videos del mundo real.
-Red Neuronal Recurrente (RNN): Las Redes Neuronales Recurrentes fueron creadas para resolver el problema de datos de entrada secuenciales en series temporales. La entrada de una RNN está compuesta por la entrada actual y muestras anteriores. Como resultado, las conexiones de los nodos crean un gráfico dirigido. Además, cada neurona en una RNN tiene una memoria interna que almacena la información de los cálculos de muestras anteriores. Debido a su superioridad en el procesamiento de datos con una longitud de entrada variable, los modelos de RNN son comúnmente utilizados en el procesamiento del lenguaje natural (NLP). El objetivo de la inteligencia artificial en este caso es crear un sistema que pueda entender lenguajes naturales hablados por humanos, como la modelización del lenguaje natural, la incrustación de palabras y la traducción automática.
Cada capa sucesiva en una RNN está compuesta por funciones no lineales de sumas ponderadas de salidas y el estado precedente. Como resultado, la unidad básica de una RNN se denomina "célula", y cada célula está compuesta por capas y una sucesión de células que permiten que los modelos de redes neuronales recurrentes se procesen secuencialmente.
-Red Neuronal Modular: Esta red está compuesta por numerosas pequeñas redes neuronales en lugar de ser una sola red. Las subredes se combinan para formar una red neuronal más grande, que opera de manera independiente para lograr un objetivo común. Estas redes son extremadamente útiles para descomponer un problema grande en problemas más pequeños y luego resolverlo.
¿Qué es el Forward y el Back Propagation en el contexto del Deep Learning?
Propagación hacia adelante (Forward):
Durante la propagación hacia adelante, las entradas se introducen en la red neuronal comenzando desde la capa de entrada. Estas entradas se multiplican por los pesos asociados con cada conexión y se pasan a través de funciones de activación en cada nodo de las capas ocultas. La salida de cada nodo se convierte en la entrada para la siguiente capa hasta que se alcanza la capa de salida final. Este proceso propaga la información hacia adelante a través de la red, de ahí el nombre de "propagación hacia adelante". En la capa de salida, la red produce predicciones o salidas basadas en los datos de entrada.
Propagación hacia atrás (Back Propagation):
La retropropagación es el proceso de actualización de los pesos de la red neuronal basado en el error entre la salida predicha y la salida objetivo real. Implica propagar el error hacia atrás a través de la red para ajustar los pesos de manera que se minimice el error. El proceso comienza con el cálculo de la derivada del error para las activaciones de la capa de salida comparando la salida predicha con la salida objetivo. Luego, la derivada del error se propaga hacia atrás a través de la red para calcular las derivadas del error con respecto a las activaciones en las capas ocultas. Este proceso continúa hasta que se calculan las derivadas del error con respecto a todos los pesos en la red. Finalmente, los pesos se actualizan utilizando estas derivadas para minimizar el error en la próxima iteración o época de entrenamiento. Este proceso iterativo de propagación hacia adelante y hacia atrás se repite hasta que la red neuronal converge a una solución satisfactoria, aprendiendo efectivamente a mapear las entradas a las salidas.
NORMALIZACIÓN DE LOS DATOS
En muchas ocasiones, van a leer o escuchar que estos algoritmos necesitan la data normalizada para poder trabajar mejor en tareas de clasificación o regresión. ¿Y para qué usamos esto? ¿Qué necesidad tiene?
La Normalización de Datos es una técnica en la cual los datos se transforman de tal manera que sean adimensionales o tengan una distribución similar. También se conoce como estandarización y escala de características. Es un procedimiento de preprocesamiento para los datos de entrada que elimina datos redundantes del conjunto de datos. La normalización proporciona un peso/importancia igual a cada variable, asegurando que ninguna variable individual sesgue el rendimiento del modelo a su favor simplemente porque es más grande. Mejora enormemente la precisión del modelo al convertir los valores de las columnas numéricas en un conjunto de datos a una escala similar sin distorsionar el rango de valores.
Algunos métodos para normalizar los datos antes de pasárselos al algoritmo, son los siguientes, a saber:
-Reescalado: El reescalado de datos es el proceso de multiplicar cada miembro de un conjunto de datos por un término constante k, o cambiar cada entero x a f(X), donde f(x) = kx y k y x son ambos valores reales. El enfoque más simple de todos, el reescalado (también conocido como "normalización min-max"), se calcula como:
f(x) = x -Min(x) / max(x) - min(x)
Esto representa el factor de reescalado para cada punto de datos x.
-Normalización por Media: En el proceso de transformación, este enfoque utiliza la media de las observaciones:
f(x) = x - media(x) / rango(x)
Esto representa el factor de normalización por media para cada punto de datos x.
-Normalización Z-score: Esta técnica, también conocida como estandarización, utiliza el Z-score o "puntuación estándar". SVM y la regresión logística son dos ejemplos de algoritmos de aprendizaje automático que lo utilizan:
f(x) = x - media(x) / desviación estándar (x)
Esto representa el Z-score.
HIPERPARÁMETROS EN EL CONTEXTO DE DEEP LEARNING
Los hiperparámetros son variables que determinan la topología de la red (por ejemplo, el número de unidades ocultas) y cómo se entrena la red (por ejemplo, la tasa de aprendizaje). Se establecen antes de entrenar el modelo, es decir, antes de optimizar los pesos y los sesgos. A continuación, se presentan algunos ejemplos de hiperparámetros:
Número de capas ocultas(Number of hidden layers): Con técnicas de regularización, muchas unidades ocultas dentro de una capa pueden aumentar la precisión. Puede ocurrir un subajuste si se reduce el número de unidades.
Tasa de aprendizaje(Learning Rate): La tasa de aprendizaje es la velocidad a la que se actualizan los parámetros de una red. El proceso de aprendizaje se ralentiza con una tasa de aprendizaje baja, pero eventualmente converge. Una tasa de aprendizaje más rápida acelera el proceso de aprendizaje, pero puede que no converja. Por lo general, se prefiere una tasa de aprendizaje decreciente.
FUNCIÓN DE ACTIVACIÓN - DEFINICIÓN Y CUÁL ES SU USO
La función de activación de una red neuronal artificial es una función que se introduce para ayudar a la red a aprender patrones complejos en los datos. En comparación con un modelo basado en neuronas visto en nuestros cerebros, la función de activación es responsable de determinar qué se debe activar para la siguiente neurona al final del proceso. En una RNA, una función de activación realiza el mismo trabajo. Toma la señal de salida de la celda anterior y la convierte en un formato que se puede utilizar como entrada para la siguiente celda.
La función de activación introduce no linealidad en la red neuronal, lo que le permite aprender funciones más complejas. La red neuronal solo sería capaz de aprender una función que sea una combinación lineal de sus datos de entrada si no tuviera la función de activación.
La función de activación convierte las entradas en salidas. La función de activación se encarga de determinar si una neurona debe ser estimulada o no. Llega a una decisión calculando el total ponderado y luego agrega sesgo. El objetivo principal de la función de activación es introducir no linealidad en la salida de una neurona.
¿Que son los Epochs en el contexto del Deep Learning a la hora de construir el modelo?
Un "epochs" es un término utilizado en el aprendizaje profundo que se refiere al número de pasadas que ha realizado el algoritmo de aprendizaje profundo a través de todo el conjunto de datos de entrenamiento. Los "batches" son comúnmente utilizados para agrupar conjuntos de datos (especialmente cuando la cantidad de datos es muy grande). El término "iteración" se refiere al proceso de ejecutar un batch a través del modelo. El número de épocas es igual al número de iteraciones si el tamaño del batch es todo el conjunto de datos de entrenamiento. Esto frecuentemente no es el caso por razones prácticas. Se utilizan varias épocas en la creación de muchos modelos.
La relación general dada es:
d x e = i x b
Donde:
- \( d \) es el tamaño del conjunto de datos.
- \( e \) es el número de épocas.
- \( i \) es el número de iteraciones.
- \( b \) es el tamaño del lote (batch size).
Ahora, ¿cómo determino el número de neuronas y de capas ocultas que debería tener la red neuronal?
No hay una regla clara y rápida para determinar el número exacto de neuronas y capas ocultas necesarias para diseñar la arquitectura de una red neuronal para un problema empresarial dado. El tamaño de la capa oculta en una red neuronal debería estar en algún punto entre el tamaño de las capas de salida y el de las capas de entrada. Sin embargo, hay algunas formas básicas que pueden ayudarte a comenzar a construir una arquitectura de red neuronal:
1. El mejor método para abordar cualquier problema único de modelado predictivo del mundo real es comenzar con una experimentación sistemática básica para ver qué funcionaría mejor para cualquier conjunto de datos dado, basado en la experiencia previa trabajando con redes neuronales en situaciones del mundo real similares.
2. La configuración de la red puede ser elegida en función de la comprensión del dominio del problema y la experiencia previa con redes neuronales. El número de capas y neuronas utilizadas en problemas similares siempre es un buen punto de partida al evaluar la configuración de una red neuronal.
3. Es mejor comenzar con una arquitectura de red neuronal simple y aumentar gradualmente la complejidad de la red neuronal en función de la salida predicha y la precisión. A medida que se evalúa el desempeño del modelo y se comprende mejor el problema, se pueden introducir capas adicionales, neuronas y técnicas de regularización para mejorar la capacidad del modelo para capturar patrones complejos en los datos. Este enfoque gradual permite un desarrollo más controlado del modelo y ayuda a evitar el sobreajuste a medida que se agrega complejidad.
ENTENDIENDO EL DROPOUT
La técnica de Dropout es un enfoque de regularización que ayuda a evitar el sobreajuste y, por lo tanto, mejora la generalización del modelo (es decir, el modelo predice la salida correcta para la mayoría de las entradas en general, en lugar de estar limitado solo al conjunto de datos de entrenamiento). En general, se debe utilizar un valor de Dropout bajo, entre el 20 por ciento y el 50 por ciento de las neuronas, siendo el 20% un punto de partida decente. Una probabilidad demasiado baja no tiene efecto, mientras que un número demasiado alto hace que la red aprenda insuficientemente.
Cuando se aplica dropout en una red más grande, es más probable que se obtengan mejores resultados porque el modelo tiene más oportunidades para aprender representaciones independientes.
DIFERENTES TIPOS DE FUNCIONES DE ACTIVACIÓN
Función Sigmoide: La función sigmoide es una función de activación no lineal en una red neuronal artificial que se utiliza principalmente en redes neuronales de alimentación directa. Es una función real diferenciable con derivadas positivas en todas partes y un cierto grado de suavidad, definida para valores de entrada reales. La función sigmoide se encuentra en la capa de salida de los modelos de aprendizaje profundo y se utiliza para prever salidas basadas en probabilidades. La función sigmoide se escribe de la siguiente manera:
sigma(x) = 1 / 1+e^-x
Función Tangente Hiperbólica (Tanh): La función Tangente Hiperbólica (Tanh) es una función más suave y centrada en cero que tiene un rango de -1 a 1. La salida de la función tanh se representa como:
tanh(x) = e^x - e^-x / e^x + e^-x
Debido a que proporciona un mejor rendimiento de entrenamiento para redes neuronales multicapa, la función tanh se utiliza considerablemente más que la función sigmoide. La principal ventaja de la función tanh es que proporciona una salida centrada en cero, lo que ayuda con la retropropagación.
Función Somax: La función somax es otro tipo de función de activación utilizada en redes neuronales para generar una distribución de probabilidad a partir de un vector de números reales. Esta función devuelve un número entre 0 y 1, con la suma de las probabilidades igual a 1. La función somax se escribe de la siguiente manera:
somax (x) = e^x / ∑_(i=1)^n e^(x_i)
Esta función se utiliza más comúnmente en modelos multinivel, devolviendo probabilidades para cada clase, con la clase objetivo teniendo la mayor probabilidad. Se puede encontrar en prácticamente todas las capas de salida de la arquitectura de aprendizaje profundo.
Función Sosign: Esta función se utiliza más comúnmente en problemas de cálculo de regresión y aplicaciones de texto a voz basadas en aprendizaje profundo. Es un polinomio cuadrático con la siguiente representación:
sosign(x) = x / 1+IxI
Unidad Lineal Rectificada (ReLU): La función de la unidad lineal rectificada (ReLU) es una función de aprendizaje rápido de inteligencia artificial que promete ofrecer un rendimiento de vanguardia y resultados sobresalientes. En el aprendizaje profundo, la función ReLU supera a otras funciones de activación como las funciones sigmoide y tangente hiperbólica en términos de rendimiento y generalización. La función es una función aproximadamente lineal que conserva las características de los modelos lineales, facilitando la optimización de los enfoques de descenso de gradiente. En cada elemento de entrada, la función ReLU realiza una operación de umbral, estableciendo todos los valores menores que cero en cero. Por lo tanto, la ReLU se escribe como:
ReLU = Max(0, x)
Función de Unidad Lineal Exponencial (ELU): La función de unidades lineales exponenciales (ELU) es un tipo de función de activación que se puede utilizar para acelerar el entrenamiento de redes neuronales (al igual que la función ReLU). La principal ventaja de la función ELU es que puede resolver el problema del gradiente desvaneciente al emplear la identidad para valores positivos y mejorar las propiedades de aprendizaje del modelo. La función de unidad lineal exponencial tiene la siguiente representación:
ELU(x) = { x si x > 0 α(e^x - 1) si x ≤ 0
donde \( \alpha \) es un parámetro de pendiente positiva que controla el valor negativo de la función para valores de entrada negativos.
PARA FINALIZAR, VEMOS LAS DIFERENCIAS ENTRE EL DEEP LEARNING Y EL MACHINE LEARNING
-Deep Learning: El Aprendizaje Profundo es una subclase del Aprendizaje Automático en la que se vinculan una red neuronal recurrente y una red neuronal artificial. Los algoritmos se construyen de la misma manera que los algoritmos de aprendizaje automático, sin embargo, hay muchos más niveles de algoritmos. La red neuronal artificial se refiere a todas las redes del algoritmo juntas. En términos mucho más simples, imita el cerebro humano al conectar todas las redes neuronales en el cerebro, que es el concepto de aprendizaje profundo. Utiliza algoritmos y una técnica para abordar todo tipo de problemas complejos.
-Machine Learning: El Machine Learnig es un subconjunto de la Inteligencia Artificial (IA) que permite a un sistema aprender y crecer a partir de sus experiencias sin tener que ser programado hasta ese nivel. El Aprendizaje Automático utiliza datos para aprender y obtener resultados precisos. Los algoritmos de aprendizaje automático tienen la capacidad de aprender y mejorar su rendimiento mediante la obtención de más datos. El Aprendizaje Automático se emplea actualmente en vehículos autónomos, detección de fraude cibernético, reconocimiento facial y sugerencia de amigos en Facebook, entre otras aplicaciones.
El contenido de este post fue redactado por Gabriel Gastón Guardia, Co - Fundador de Optima Consulting & Managemet LLC. El mismo constituye una apreciación personal y divulgación científica informativa.
Perfil de LinkedIn : www.linkedin.com/in/gabriel-gastón-guardia-a77a10183
Contacto : gonzalezguardia1.618@gmail.com